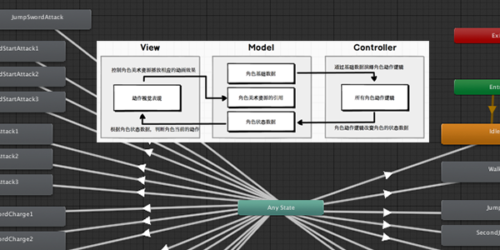
Unity URP+Micro Gbuffer自定义延迟管线

用Micro Gbuffer把URP管线改造成Forward+Deferred Lighting
Unity提供的SRP(Scriptable Render Pipeline可编程渲染管线)通过C#脚本就可以方便的自定义渲染管线。由于URP目前只支持forward管线,所以我尝试了一些办法将他改造成了支持deferred lighting的管线。也针对移动端做了一些优化。
改造的前提是,我不想改动URP package里的内容,以免以后跟进URP版本更新很麻烦。所以改动部分都只在外部,虽然做起来有点麻烦,也有不少缺点。但这方式比较适合小团队快速开发,不需要额外的引擎团队去魔改引擎和持续维护。
Micro Gbuffer
首先,URP默认的forward pass只输出一张32位的Color Buffer(R8G8B8A8或者R11G11B10),这部分不动源码就没法改成MRT输出。所以我选择用Micro G-buffer的方式来让这一张Color Buffer输出所有后续Deferred Lighting阶段需要的G-buffer信息。
Micro Gbuffer目前在Cry Engine里比较推崇,我的相关代码也是从Cry Engine里抄来的。其原理就是通过交错的棋盘格像素排布,把Albedo,Normal,Metallic和Roughnes等信息存进一张Buffer里。像素交错排布的优势就是可以利用GPU硬件特性提升采样Cache命中率(简单说就是提高采样贴图的效率)。
这里有Cry Engine官方给出的基于Micro Gbuffer的Moblie平台Demo视频:
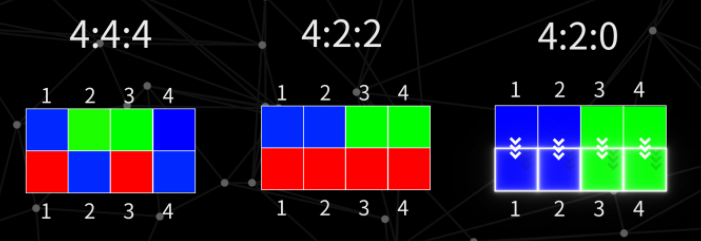
Albedo原本需要RGB三个通道,但其实RGB三个颜色通道的有效精度并不相同。所以可以采用视频编码领域的做法,转成YCbCr格式。熟悉摄影摄像的同学应该了解420-8bit,422-10bit这些名词,其实就是源自这种视频压缩方式。具体来说就是用8个像素一组储存颜色信息,其中色彩的亮度(Y)贡献最大,因为人眼对亮度最敏感,色相(CbCr)其次,所以一般Y会给满4格,CbCr各给到2格或者1格。这样储存虽然会有精度丢失,但是文件尺寸可以极大压缩,并且人眼感受上也不会看出明显的画面粗糙。

关于YCbCr(或者叫YUV)详细介绍可以参考以下链接:
https://zhuanlan.zhihu.com/p/41958574
https://en.wikipedia.org/wiki/YCbCr
https://en.wikipedia.org/wiki/YUV
其次是Normal信息的压缩。NormalWS也有3个通道,但有办法可以压缩进2个通道。先把世界空间的Normal WS转到相机空间的Normal VS,因为View Space下的法线Z永远不可能为负值,可以节省一半精度。然后通过Octahedral Normal Vectors (ONV)的转换方式,把球面法线转换到正八面体上。
压缩Normal的方式还有很多,具体可参考链接文章:
https://aras-p.info/texts/CompactNormalStorage.html
http://jcgt.org/published/0003/02/01/paper.pdf
大致的Micro Gbuffer的编码方式如下图:
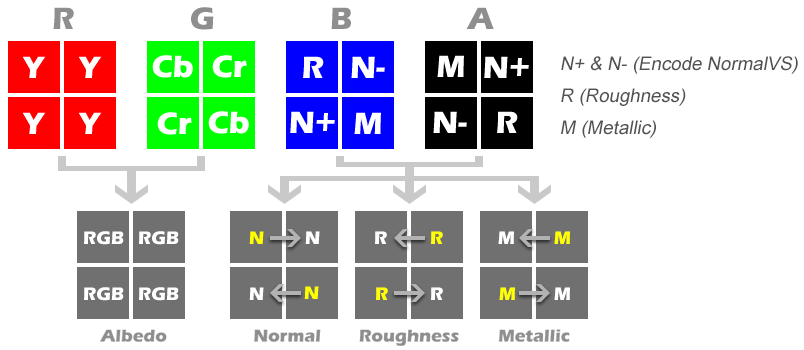
- Albedo最重要,所以占了最大比重
- Normal的两个值必须在同一个像素点上,所以分在2个通道里。
- Metallic和Roughness贡献度最低,只在BA两个通道各占一格,交错排布。
Decode Micro Gbuffer的时候也做了一些优化:
- 对应像素交错排布,可以通过像素坐标奇偶值计算采样,代码也比较简洁
- CbCr的提取是采样了周围4个像素,通过亮度Y的相似度计算权重取值。
- Normal,Roughness和Metallic则是左移一位取值,所以lighting结果会看出来精度缺失,但分辨率够大的时候是看不出来的,这也可以搭配TAA解决。
Cry Engine的相应Encode和Decode代码参考:
void EncodeMicroGBuffer(MaterialAttribsCommon attribs, inout half4 bufferA, int2 WPos)
{
float3 normalView = mul((float3x3)CV_ViewMatr, attribs.NormalWorld);
float2 normalEnc = normalView.xy * rsqrt(8 * normalView.z + 8) + 0.5;
bool bChecker0 = (WPos.x & 1) == (WPos.y & 1);
float3 baseColorYCC = EncodeColorYCC(attribs.Albedo);
bufferA.xy = bChecker0 ? baseColorYCC.xy : baseColorYCC.xz;
bufferA.z = bChecker0 ? attribs.Smoothness : normalEnc.x;
bufferA.w = bChecker0 ? GetLuminance(attribs.Reflectance) : normalEnc.y;
}
//=======================================
// Decode Micro GBuffer
{
float4 uGBuf = GBufferA[pixCoord];
float4 uGBuf1 = GBufferA[pixCoord + int2( 1, 0)];
float4 uGBuf2 = GBufferA[pixCoord + int2(-1, 0)];
float4 uGBuf3 = GBufferA[pixCoord + int2( 0, 1)];
float4 uGBuf4 = GBufferA[pixCoord + int2( 0, -1)];
// Edge-directed reconstruction filter
const float edgeThreshold = 0.1;
float4 lum = float4(uGBuf1.x, uGBuf2.x, uGBuf3.x, uGBuf4.x);
float4 weights = 1 - step(edgeThreshold, abs(lum - uGBuf.x));
float weightSum = dot(weights, 1);
weights.x = (weightSum == 0) ? 1 : weights.x;
float invWeightSum = (weightSum == 0) ? 1 : rcp(weightSum);
// Reconstruct missing components
float yy = dot(weights, float4(uGBuf1.y, uGBuf2.y, uGBuf3.y, uGBuf4.y)) * invWeightSum;
float zz = dot(weights, float4(uGBuf1.z, uGBuf2.z, uGBuf3.z, uGBuf4.z)) * invWeightSum;
float ww = dot(weights, float4(uGBuf1.w, uGBuf2.w, uGBuf3.w, uGBuf4.w)) * invWeightSum;
bool bChecker0 = ((int)IN.WPos.x & 1) == ((int)IN.WPos.y & 1);
attribs.Smoothness = bChecker0 ? uGBuf.z : zz;
attribs.Reflectance = bChecker0 ? uGBuf.w : ww;
attribs.Albedo = DecodeColorYCC(float3(uGBuf.x, bChecker0 ? uGBuf.y : yy, bChecker0 ? yy : uGBuf.y));
// Decode normal
float2 normEnc = float2(bChecker0 ? zz : uGBuf.z, bChecker0 ? ww : uGBuf.w) * 4 - 2;
float f = dot(normEnc, normEnc);
attribs.NormalWorld.xy = normEnc * sqrt(1 - f / 4);
attribs.NormalWorld.z = 1 - f / 2;
attribs.NormalWorld = mul(attribs.NormalWorld, (float3x3)CV_ViewMatr);
}CryEngine Git Hub 相关代码链接:
自定义管线
初步的URP管线流程修改如下:
- Forward阶段自定义不透明物体shader,输出经过Micro Gbuffer编码的信息。
- 在Opaque渲染完之后插入render feather,做Decode Micro Gbuffer同时输出所有Gbuffer信息的MRT。
- 然后走传统的Deferred Lighting,输出主光源lighting完的scene color。
- 最后由cpu传入附近需要渲染的点光源信息,逐个渲染点光源的lighting。
这样做的渲染结果乍看还凑合,但是在亮度不足的区域会明显看到精度丢失,从32位的Cbuffer中编码出这么多信息肯定精度是不够的。

物体边缘因为棋盘格采样的问题,在物体边缘颜色差别较大的地方也会有明显的过曝/过暗的像素情况。如下图。

所以我换了种方式,让主光源的lighting直接在forward阶段做好,直接输出高精度的scene color。后续Deferred阶段只做点光源的Lighting,因为点光源可以只做BRDF,对Normal精度要求不是很高。
其forward部分的渲染输出结果如下:

这样做其实给Gbuffer提供的Albedo不是原始BaseColor了,而是经过主光源lighting过后的Scene Color。虽然不精确,但后面只是给点光源做Lighting,大多数情况下是不会看出明显问题的。
天空球优化
天空球一般不需要Deferred Lighting,所以可以用Stencil拆出来画。我的初步做法是直接在Deferred Lighting之后再画天空球,但这有个问题,就是前期Micro Gbuffer阶段由于天空球的部分没有Micro Gbuffer着色,所以Opaque物体的边缘由于棋盘格采样的问题会计算出过爆/过暗的像素值。(貌似Micro Gbuffer最大的问题就是边缘像素取值差异过大就会过曝/过暗)

解决的方法就是在Opaque对象绘制完就立刻绘制天空球,并且输出2张MRT,一张Encode Micro Gbuffer的直接输出到Color Buffer上,另一张未编码的Scene Color给之后Deferred Lighting完再blend到Color Buffer上。

优化后的管线如下图:
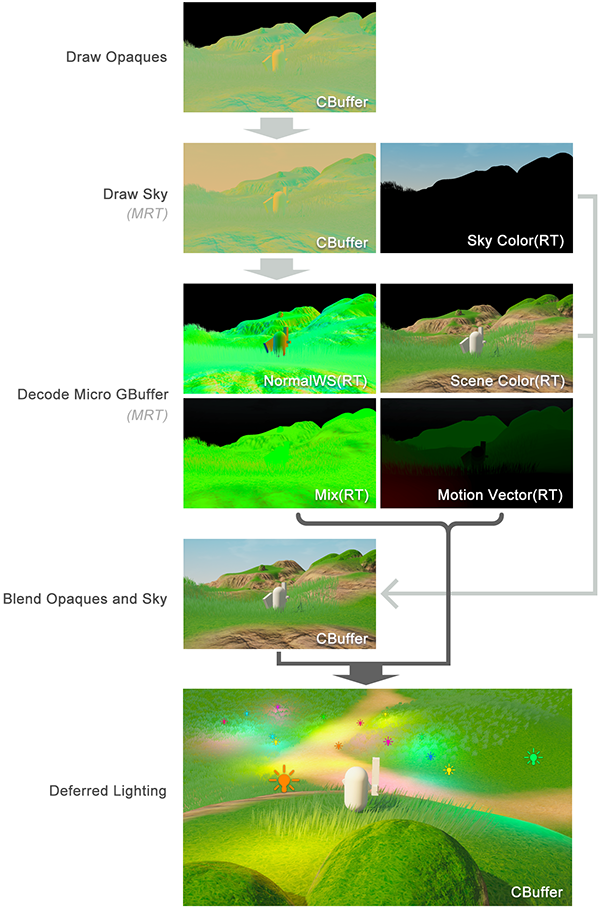
- Forward阶段绘制Encode Micro GBuffer的Opaques对象,同时标记stencil。
- 在Opaques之后绘制天空球,利用stencil只绘制天空部分,输出2张MRT,第一张Encode Micro GBuffer的直接绘制到Cbuffer上,与之前Opaques的合并成一张完整的Micro GBuffer;第二张输出最终的天空颜色。
- 之后做Decode Micro Gbuffer,利用stencil只绘制Opaques,同时输出MRT(后面可以压缩),给之后的Deferred Lighting用。
- 合并Opaques和Sky的颜色,输出到CBuffer上。
- 最后做Deferred Lighting。
目前我把管线做成了这样,不过Cry Engine是用Tile Based Deferred的,后续点光源Lighting阶段更加优化。以后有时间再尝试改成那样看看。
GBuffer MRT优化
在Decode Micro Gbuffer之后输出的MRT也可以再优化一下。其中Normal只有一半分辨率,而Roughness和Metallic可以再让出一半像素给Occlusion和HDR Scale。然后输出的信息可以再次按棋盘格的排布合并在一张RT上。这样做也是利用了采样Catch命中率的优化。输出3张格式为R11G11B10的MRT,这样存储信息的精度更高,如下图:
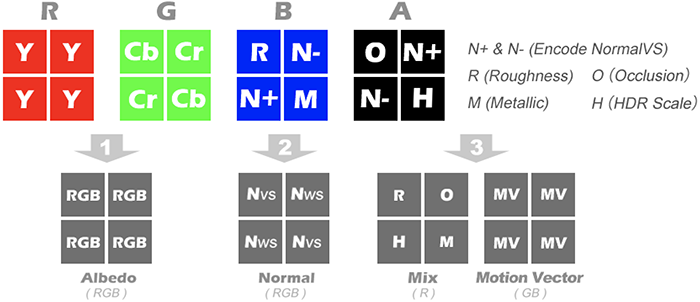
- 第一张是Scene Color或者Albedo
- 第二张是NormalVS和NormalWS各占一半
- 第三张的R通道存了Roughness,Metallic, Occlusion和HDR Scale;GB通道存Motion Vector。
其中额外存的NormalVS和Motion Vector可以给之后SSGI,Motion Blur之类的后处理使用。
或者也可以再精简一点,只用2张MRT。如下图
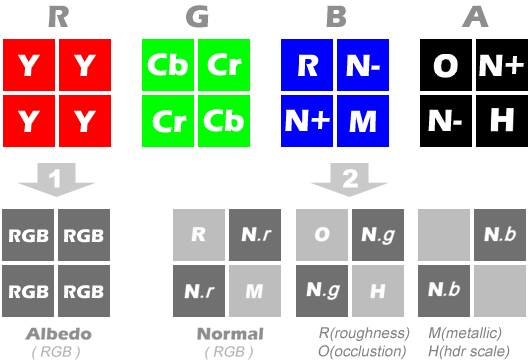
- 第一张是Scene Color或者Albedo
- 第二张一半是NormalWS,另一半的RG通道存了Roughness,Metallic, Occlusion和HDR Scale。B通道还空了2个像素可以存些其他信息,例如BRDF预计算的信息。
点光源Deferred Lighting
参考GTA5的做法,就是只关心近处的点光源,远处替换成Halo之类的billboard的方式。
- CPU收集附近的点光源信息List,传递给Shader。
- 在Decode Micro Gbuffer之后遍历点光源List,用2个pass绘制(第一个几何,第二个着色)。
- 三层LOD:近处根据距离做点光源intensity的fade过度,中距离替换成Halo,最远处就不渲染了
总结
这套做法虽然有点费事,渲染精度也不高,但是对于移动端来说刚好可以靠Micro Gbuffer来节省带宽,同时也能利用到SRP Batch和Forward管线的一些优势,而且能在不改URP源码的情况下使用,方便引擎升级更新。
Micro Gbuffer的编码方式可以根据项目实际需要来设计,可以在输出的MRT上多存一些Lighting阶段的input预计算的信息。
如果用Cry Engine的Tile Based Deferred方式应该会更适合这套流程,后续我会再改改看。
同事还推荐了《地平线-零之曙光》里的Checkerboard方式的AA来提高精度,原理就是用2帧半分辨率的Cbuffer合成一张高精度的Cbuffer,我之后会去研究研究,具体可参考链接文章:
https://www.guerrilla-games.com/read/decima-engine-advances-in-lighting-and-aa